
Populating a mobile phone database manually is tedious, error-prone, and extremely time-consuming.
In this project, a mobile company needed up-to-date information about thousands of devices, including specifications, images, and reviews. Manual collection could take days and require multiple team members, making it a perfect candidate for automation.
This case study explains how I built a scalable web crawler service that automated the data collection workflow, drastically reducing manual effort and ensuring accurate, timely database updates.
The Challenge
The client needed a complete mobile phone database containing:
- Brand and model information
- Images, URLs, and descriptive titles
- Detailed specifications (display, camera, battery, chipset, RAM, etc.)
- User reviews and metadata
Manual entry presented these issues:
- Slow and repetitive
- Prone to errors
- Difficult to scale with frequent phone releases
- Resource-intensive, requiring multiple employees
Goals
The automation needed to:
- Crawl all brands and phone models from a central website
- Extract full specifications for each device
- Capture images, URLs, and reviews
- Populate the client database automatically
- Allow incremental updates to avoid duplicates
- Be scalable, maintainable, and robust
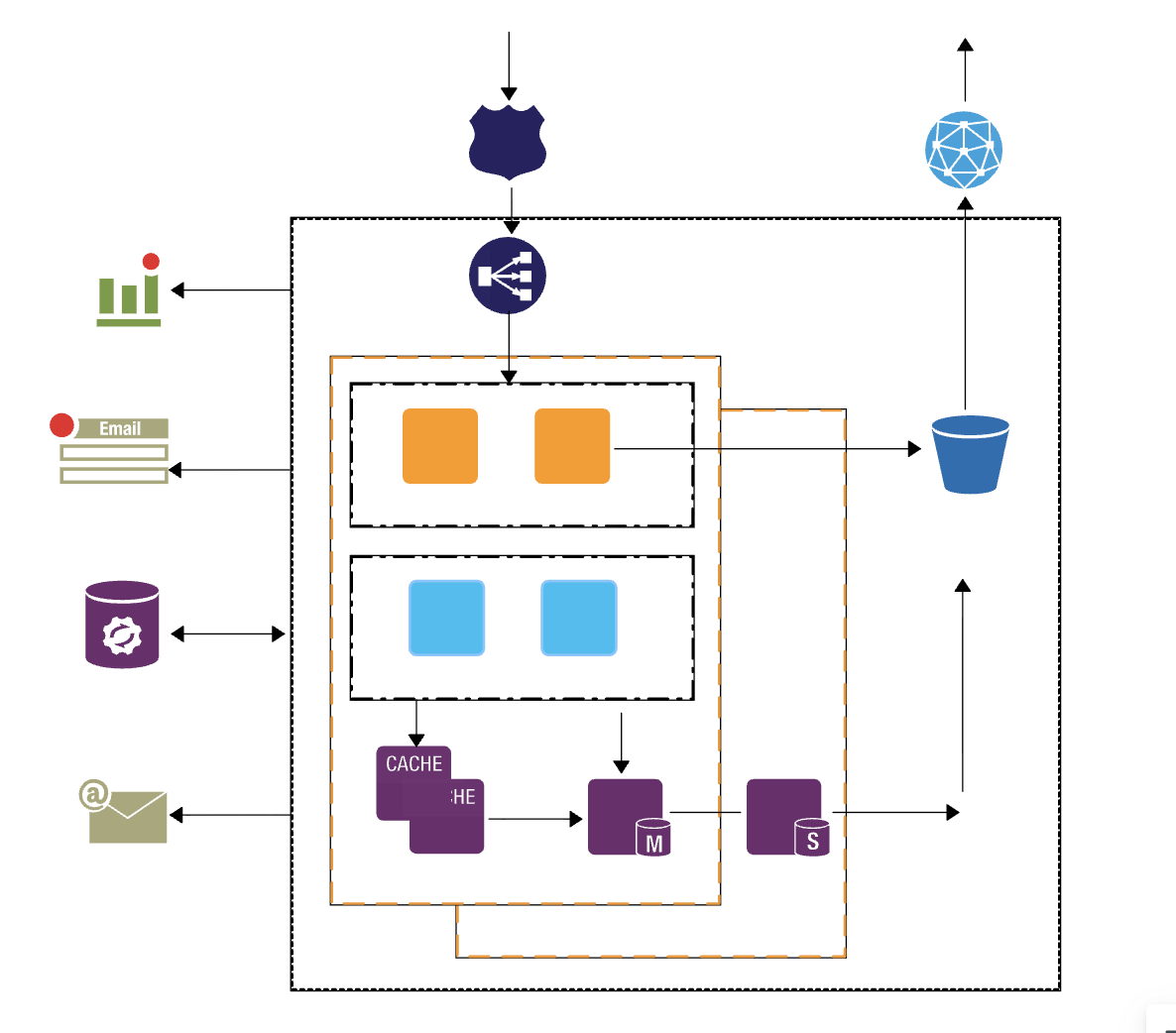
Architecture Overview
The architecture consists of a Node.js crawler service using:
- Restify – API server
- Axios & Request – HTTP client for fetching pages
- Cheerio – HTML parsing
- Database API – Integration to store crawled data
Steps:
- Brand Extraction – Crawl all phone brands from GSM Arena.
- Phone List Extraction per Brand – Crawl phone models with basic metadata.
- Phone Details Extraction – Extract detailed specs, images, and quick specs.
- Review Extraction – Fetch all reviews with metadata.
- Database Integration – Insert/update data automatically.
- Incremental Crawling – Skip already stored phones to prevent duplicates.
Algorithm (Automated Crawling Flow)
-
Fetch all phone brands from the source website.
-
For each brand:
a. Fetch the list of phones (handling pagination).
b. For each phone:i. Check if phone already exists in the database.
ii. Fetch detailed phone specifications.
iii. Fetch images, URLs, and quick specs.
iv. Fetch reviews if available.
v. Save the data to the client database. -
Repeat until all phones are crawled or batch limit reached (e.g., 65 phones per crawl).
-
Return success once all data is collected.
Clean Implementation
import restify from "restify";
import cheerio from "cheerio";
import axios from "axios";
import request from "request";
import corsMiddleware from "restify-cors-middleware";
const URI = "https://www.gsmarena.com";
const cors = corsMiddleware({ preflightMaxAge: 5, origins: ["*"] });
const server = restify.createServer();
server.pre(cors.preflight);
server.use(cors.actual);
server.use(restify.plugins.queryParser());
/**
* Fetch all phone brands
*/
async function fetchBrands(req, res, next) {
request({ url: `${URI}/makers.php3`, headers: { "User-Agent": "request" } }, (err, _, html) => {
if (err) return res.send({ error: "Failed to fetch brands" });
const $ = cheerio.load(html);
const brands = $("table td")
.map((_, el) => ({
name: $(el).find("a").text().replace(" devices", "").trim(),
devices: $(el).find("span").text().replace(" devices", "").trim(),
url: $(el).find("a").attr("href"),
}))
.get();
res.send(brands);
next();
});
}
/**
* Fetch phones for a specific brand
*/
async function fetchBrandPhones(req, res, next) {
const { id: brandId } = req.params;
request({ url: `${URI}/${brandId}`, headers: { "User-Agent": "request" } }, (err, _, html) => {
if (err) return res.send({ error: "Failed to fetch phones" });
const $ = cheerio.load(html);
const phones = $(".makers li")
.map((_, el) => ({
name: $(el).find("span").text(),
img: $(el).find("img").attr("src"),
url: $(el).find("a").attr("href"),
description: $(el).find("img").attr("title"),
}))
.get();
const nextPage = $("a.pages-next").attr("href");
res.send({ phones, nextPage });
next();
});
}
/**
* Fetch detailed specs for a phone
*/
async function fetchPhoneDetails(req, res, next) {
const { phone } = req.params;
request({ url: `${URI}/${phone}`, headers: { "User-Agent": "request" } }, (err, _, html) => {
if (err) return res.send({ error: "Failed to fetch phone details" });
const $ = cheerio.load(html);
const quickSpec = {
display: $("span[data-spec=displaysize-hl]").text(),
camera: $(".accent-camera").text(),
ram: $(".accent-expansion").text(),
battery: $(".accent-battery").text(),
chipset: $("div[data-spec=chipset-hl]").text(),
};
const specDetail = $("table")
.map((_, el) => ({
category: $(el).find("th").text(),
specs: $(el)
.find("tr")
.map((__, row) => ({
name: $("td.ttl", row).text(),
value: $("td.nfo", row).text(),
}))
.get(),
}))
.get();
const title = $(".specs-phone-name-title").text();
const img = $(".specs-photo-main a img").attr("src");
const imgUrl = $(".specs-photo-main a").attr("href");
res.send({ title, img, imgUrl, quickSpec, specDetail });
next();
});
}
// Define routes
server.get("/gsmarena/brands", fetchBrands);
server.get("/gsmarena/brand/:id", fetchBrandPhones);
server.get("/gsmarena/phone/:phone", fetchPhoneDetails);Conclusion
This project transformed a manual, multi-day process of collecting mobile phone data into a fully automated, efficient, and reliable pipeline.
By leveraging web scraping, structured data extraction, and automated database integration, the client gained:
- Rapid database population with minimal human effort
- Up-to-date, accurate device information for all brands and models
- Scalable and repeatable processes to handle future phone releases
- Reduced operational errors and improved data reliability
This automation not only solved the immediate problem of slow, error-prone manual entry but also established a robust framework for future product data collection, research, and analytics, freeing the team to focus on higher-value tasks instead of repetitive work.
Read more

Automating Mobile Phone Data Collection: Efficient Web Crawling for Database Population
A case study on building a scalable automation service to populate mobile phone data into a client database using web scraping and Node.js.

Automating EC2 & JupyterHub Provisioning: Reducing Deployment Time from Hours to Minutes
A senior-engineer case study on converting a manual AWS provisioning workflow into a fully automated system using AWS SDK, IAM, S3, and EC2 orchestration.
Architecting a Scalable Learning Management Platform with React, Node.js, and AWS
A case study on migrating a monolithic LMS to a modular, microservices-inspired architecture with high scalability, real-time analytics, and multi-role support.